




















The interdisciplinary field known as bioinformatics, which particularly integrates computer science, statistics, mathematics, and biology, has been at the forefront of revolutionising research in the life sciences. Its tremendous impact reaches from deciphering the human DNA to comprehending intricate biological processes and creating cutting-edge treatments. Bioinformatics is a field that is always evolving, revealing new frontiers and trends that are shaping the landscape of biological research as data collection speeds up and technology develops. The main growing trends in bioinformatics are examined in this article along with their relevance, uses, and possible ramifications. Lets Dive in!
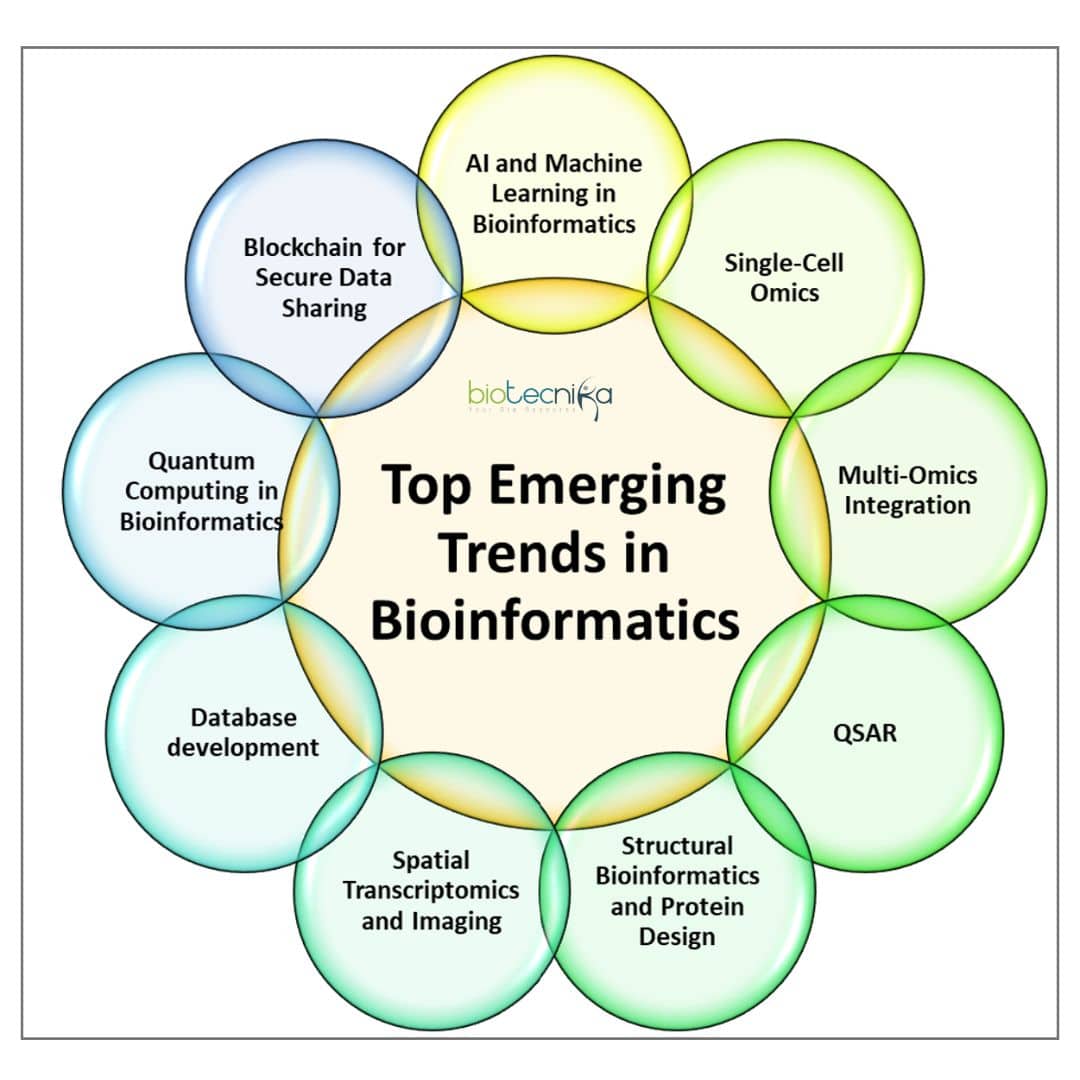
Top Emerging Trends in Bioinformatics
- AI and Machine Learning in Bioinformatics:
In the field of bioinformatics, artificial intelligence (AI) and machine learning (ML) have completely changed data analysis, pattern identification, and predictive modelling. Personalised medicine, drug discovery, and protein structure prediction are made possible by AI-powered algorithms that can extract valuable insights from large biological datasets. The field of genomics, transcriptomics, and proteomics has witnessed tremendous success with deep learning techniques like convolutional neural networks (CNNs) and recurrent neural networks (RNNs). These advancements have sped up the speed of biological discovery.
Artificial Intelligence provides a more sophisticated toolkit than traditional computing methods, making it easier to solve problems in the domains. Machine learning techniques, or developing more effective, dependable, and precise neural networks and deep learning models, are currently leading the way in AI approaches for bioinformatics and genomics. However, AI techniques are not restricted to those. Artificial intelligence can be applied to the study of molecular structures and the classification of biological data. Artificial intelligence (AI) has also been used in research on protein-protein interaction, biological/gene sequence matching, function-structure analysis, and many more areas.
Project Work Available in AI ML in Biology & Bioinformatics for 3 & 6 Months
Register at FLAT 25% Discount | Starts From 16th May 2024
Standard machine learning methodology: In the subject of computational intelligence, and particularly in machine learning, the design of the experimental phase is an important stage. To do this, it is necessary to first specify the methodology that will be used.
Even though several steps in the experimental design are shared by many research domains, the application of ML approach needs to be transversal. More specifically, we may distinguish between the subsequent processes in the machine learning methodology used in drug discovery:
1) gathering data;
2) creating mathematical descriptors;
3) identifying the optimal selection of variables;
4) training the model;
5) validating the model.
- Quantitative structure-activity relationship
The models of quantitative relationship between structure and activity (QSAR), which numerically relate the chemical structures of the molecules with their biological activity, operate under the tenets that “the structure of a molecule defines its biological activity” and “structurally similar molecules have a similar biological activity.” Through mathematical systems, it is possible to predict the physicochemical and biological fate properties that a new compound will have based on its chemical structure and previous experimental studies.
To generate a theoretical forecast of biological activity that enables the theoretical creation of potential future new pharmaceuticals without having to go through the trial-and-error process of organic synthesis, QSAR models integrate computer and statistical methodologies. It permits the elimination of some resources, including tools, materials, personnel, and equipment because it is a science that only exists virtually. Focusing on the connections between molecular structure and biological function makes the process of designing potential new medications considerably quicker and less expensive. When sufficient experimental data and facilities are unavailable, one of the best ways to accomplish compound prediction is through modelling studies like QSAR.
To carry out a QSAR study, three types of information are needed:
- Molecular structure of different compounds with a common mechanism of action
- Biological activity data of each of the ligands included in the study.
- Physicochemical properties, which are described from a set of numerical variables, obtained from the molecular structure virtually generated by computational techniques.
When analyzing results in the prospective type, one can virtually predict the biological activity of compounds that have not yet been synthesized in a short amount of time using equations or QSAR models. However, these compounds must share structural characteristics with the ligands that are included in the study in order to avoid deviating from the rules, chemical pattern, or range of values of the descriptors.
BIO-IT Career Starter Kit: FREE PDF Download
- Single-Cell Omics:
Technologies for single-cell omics have become an effective means of analysing heterogeneity inside cells and deciphering complex biological processes occurring at the single-cell level. Complex tissues may now be comprehensively profiled in terms of cell types, states, and interactions because to developments in single-cell RNA sequencing (scRNA-seq), single-cell ATAC-seq, and spatial transcriptomics.
Single-cell multiomics, which allows for the dissection of normal development and disease processes at single-cell resolution and establishes a connection between a cell’s genotype and phenotype, has supplanted bulk tissue sequencing. Additionally, single-cell multiomics will improve our comprehension of the population architectures and cellular characteristics of many tissues. It will also afford us glimpses into the interactions between these multiomic molecular layers and the intricacy that permeates all levels of biological structure.
Precision medicine and tailored therapeutics are made possible by these technologies, which provide hitherto unheard-of insights into immune cell dynamics, cancer heterogeneity, and developmental biology.
- Multi-Omics Integration:
Interpreting molecular complexity and changes at several levels, including the genome, epigenome, transcriptome, proteome, and metabolome, is necessary for a thorough knowledge of human health and disorders. Biology now depends more than ever on data produced at multiple levels, collectively referred to as “multi-omics” data, since the development of sequencing technology. The accessibility of multi-omics data has transformed the fields of biology and medicine by opening up new possibilities for integrated system-level methods.
Incorporating diverse omics data layers, such as transcriptomics, proteomics, metabolomics, and genomes, has enormous potential to provide comprehensive understanding of biological systems. Higher resolution and accuracy in identifying molecular signatures, biomarkers, and disease causes are made possible by multi-omics methods. Researchers can decipher complex genotype-phenotype relationships, disentangle intricate regulatory networks, and identify new treatment targets by utilising computational techniques and statistical models.
Ready To Add A New Dimension To Your Career? 
BRAND NEW LAUNCH Coding For Biologist Hands-on Training Program With 3 Months & 6 Months Project Work in Python, R, BioPython & CADD Biological Data Analysis
Become a BIO-CODER | Work on Projects | Publish Papers | Get Work Experience – Starts: 13th May 2024
Register Now at Early Bird Price
- Structural Bioinformatics and Protein Design:
In natural organisms, proteins are essential. They can carry out a variety of tasks in cells, including defense, transport, catalysis, and structural work. We are aware that there are numerous tools available for working with protein structural bioinformatics, which carries out operations such protein docking, protein modeling, protein molecular dynamics, protein interaction, prediction of active and binding sites, and mutation identification. However, they are typically dispersed over several web repositories.
Protein engineering, drug discovery, and protein structure prediction have all been completely transformed by developments in computational modelling and structural bioinformatics. Protein-ligand docking, homology modelling, and molecular dynamics simulations allow for the logical design of new enzymes, inhibitors, and treatments. The development of deep learning-based methods like AlphaFold has made precise protein structure prediction more practical, which has aided in de novo drug creation and drug repurposing.
These days, a growing amount of protein sequences and structures are stored in specialized databases, primarily due to advancements in genomic sequencing technologies and structure determination techniques. At first, the amino acid sequence of proteins was the only information known about them. The Protein Data Bank (PDB) will turn 50 in 2021 a list of every macromolecule structure that is currently known to us. Under Walter Hamilton’s direction, the PDB was founded at Brookhaven National Laboratory in 1971 and consists of seven structures. Structural bioinformatics has emerged as a result of the rapid expansion in the quantity of known three-dimensional macromolecular structures and the sequencing of organisms’ genomes.
The two main objectives of structural bioinformatics are to develop universal techniques for modifying data on biological macromolecules and to use these techniques to solve biological puzzles and produce new insights.
Docking: Understanding how proteins interact with ligands or with one other is crucial for a number of scientific domains, including the creation of novel medications and the understanding of molecular recognition. This led to the development of the now widely used molecular docking technology. It involves figuring out which orientation a molecule should take on in order to create a stable compound with a receptor.
Catalytic and binding site prediction: As a result of the development of genomic sequencing technology and techniques for protein sequence determination, there is currently a surge in the quantity of structures and protein sequences stored in specialized databases. One of the difficulties with proteins is predicting their function, which makes it more important to have automatic and trustworthy methods for making such predictions.
Molecular dynamics: Utilizing a numerical calculation method called molecular dynamics, molecular systems are subjected to Newton’s classical rules of motion. Force fields that spe1cify the temporal and spatial energy pattern are used to characterize the behaviour of molecules in this way. A cut-off is also constructed to find the greatest interaction distance between two atoms in addition to this approximation, in an effort to minimize the number of operations that the algorithm must finish.
Molecular visualization: Studies on the functions of proteins have greatly benefited from the development of novel experimental techniques and methods for determining the structure of molecules in three-dimensional space. New investigations were made possible by an increase in the quantity of 3D structures deposited in the Protein Data Bank (PDB) database. Numerous “molecule viewers” are accessible for free, and open-source facilitates open science with the goal of understanding structures and physical-chemical phenomena.
Top Emerging Trends in Bioinformatics – Read On for more insights!
- Spatial Transcriptomics and Imaging:
Gene expression patterns within intact tissues can be visualised and mapped with spatial precision thanks to advances in spatial transcriptomics and imaging technology. Methods such as multiplexed ion beam imaging (MIBI), spatial transcriptomics, and spatially resolved transcript amplicon sequencing (STARmap) provide information about cell-cell interactions, tissue architecture, and the spatial organisation of biological molecules. These methods allow the detection of geographically different cell populations and microenvironmental cues, with substantial ramifications in the fields of developmental biology, neurology, and cancer research.
- Quantum Computing in Bioinformatics:
Due to its ability to accelerate complex computations and simulations exponentially, quantum computing holds the potential to revolutionise the field of bioinformatics. With unmatched speed and efficiency, quantum algorithms have the ability to read genomic sequences, mimic chemical interactions, and solve optimisation problems. Algorithms for quantum machine learning provide new ways to analyse high-dimensional biological data and find hidden patterns. Though technology is still in its early stages, quantum computing has the potential to break through bioinformatics’ computational limitations and lead to revolutionary breakthroughs in the life sciences.
- Biological Database development:
In ‘‘Omics’’ era of the life sciences, data is presented in many forms, which represent the information at various levels of biological systems. Therefore, bioinformatics relies heavily on biological datasets. They provide access to a vast array of biologically significant data, such as the genome sequences of an ever-widening variety of organisms, for scientists. An overview of the main sequence databases and portals, including Ensembl, the UCSC Genome Browser, and GenBank, is given in this unit.
- Blockchain for Secure Data Sharing:
Blockchain technology is increasingly being explored to address the challenges of data privacy, security, and integrity in bioinformatics. By leveraging decentralized and immutable ledgers, blockchain platforms enable secure and transparent sharing of genomic, clinical, and research data. Smart contracts facilitate data access control, consent management, and incentivization mechanisms, fostering collaborative research while ensuring data privacy and ownership rights. Blockchain-based solutions have the potential to revolutionize data-driven research, empower patients, and accelerate biomedical innovation.
Exclusive Limited Time program – Molecular Dynamics Simulation Online Hands-on Training – Starts 10th May 2024
Conclusion:
Big data analytics, interdisciplinary cooperation, and technology innovation are driving the continued rapid breakthroughs in the field of bioinformatics. With their potential for revolutionary discoveries, individualised treatments, and better healthcare results, the new developments – Top Emerging Trends in Bioinformatics – covered in this article provide a window into the direction that biological research is headed. Accepting these patterns will be essential to maximising the promise of proteomics, genomics, and systems biology in tackling major issues in agriculture, health, and the environment as bioinformatics develops.
About the Author:
Our scientist at Biotecnika, Dr. Prakrity Singh, has compiled the above article on Top Emerging Trends in Bioinformatics. She is a dedicated computational biologist with a Ph.D. passionate about using advanced computational techniques to solve complex biological problems. As a Ph.D. Scholar (SRF) at CSIR-Indian Institute of Toxicology Research. Her research focuses on understanding atomic structures related to persistent organic pollutants and their impact on biological systems. Dr. Singh has contributed significantly to drug discovery and toxicity projects, with her work published in peer-reviewed journals. Her commitment to advancing scientific understanding with environmental protection and human health applications underscores her trailblazing role in computational biology. Dr. Singh’s expertise promises to shape the future of computational biology and its role in toxicology.












Excellent
Hi, bioinformatics is very important subject