




















CSIR NET UNIT 2 Notes – Organization of Genes & Chromosomes – Download Full PDF
CSIR NET UNIT 2 Reference Book List:
- Cell and Molecular Biology: Concepts and Experiments by Gerald Karp
- Molecular Biology of the Cell by Bruce Alberts, Alexander Johnson, Julian Lewis
- Molecular Cell Biology by Harvey Lodish, Arnold Berk, Chris A. Kaiser
- Prescott’s Microbiology by Joanne Willey, Linda Sherwood, Chris Woolverton
- Brock Biology of Microorganisms
Topics Covered under CSIR NET UNIT 2 – Organization of Genes & Chromosomes:
- Operons
- Unique & Repetitive DNA
- Interrupted genes
- Gene Families
- Structure of chromatin & Chromosomes
- Heterochromatin & Euchromatin’
- Transposons
The genetic material in a cell:
- All cells have the capability to give rise to new cells and the encoded information in a living cell is passed from one generation to another.
- The information encoding material is the genetic or hereditary material of the cell.
Prokaryotic genetic material: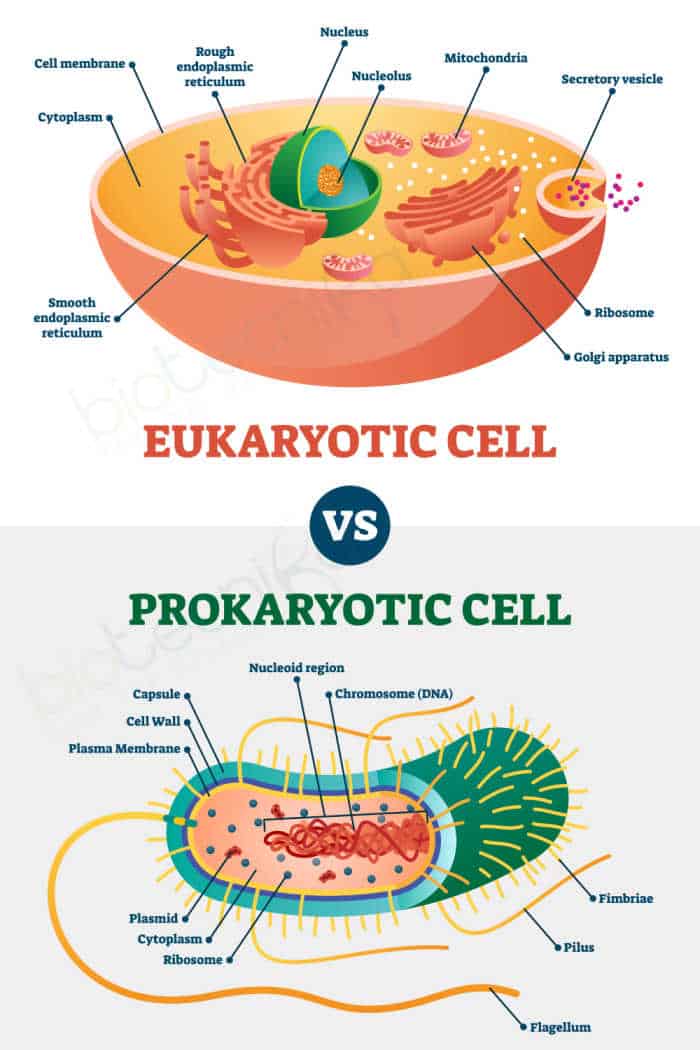
- The prokaryotic (bacterial) genetic material is usually concentrated in a specific clear region of the cytoplasm called the nucleoid.
- The bacterial chromosome is a single, circular, double-stranded DNA molecule mostly attached to the plasma membrane at one point.
- It does not contain any histone protein.
- Besides the chromosomal DNA, many bacteria may also carry extrachromosomal genetic
elements in the form of small, circular, and closed DNA molecules, called plasmids. They
generally remain floating in the cytoplasm.
Eukaryotic genetic material:
- A Eukaryotic cell has genetic material in the form of genomic DNA enclosed within the nucleus.
- Genes or the hereditary units are located on the chromosomes which exist as chromatin networks in the non-dividing cell/interphase.
GENE
- A gene is the basic physical and functional unit of heredity. Genes, which are made up of DNA, act as instructions to make molecules called proteins. Genes are made up of DNA. So genes can be defined as a basic structural and functional unit of DNA.
- Genes are organized in chromosomes
- In eukaryotes, DNA and histone proteins are packaged into structures called chromosomes.
Each chromosome is made up of DNA tightly coiled many times around proteins called histones that support its structure.
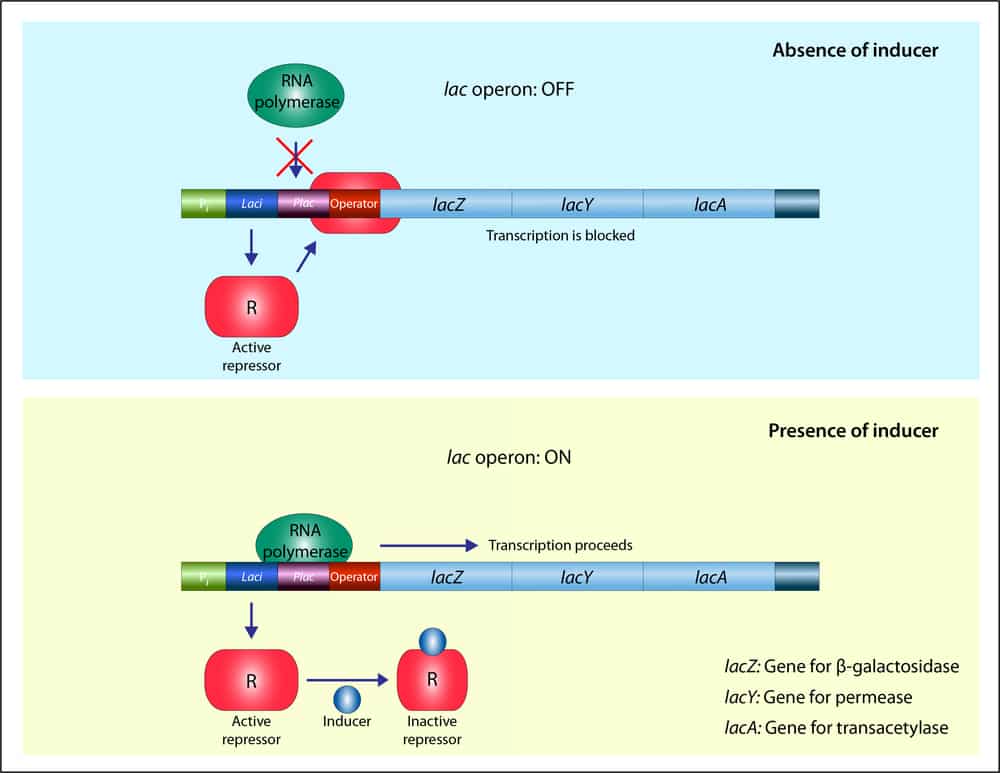
Operon
- Many prokaryotic genes are organized into operons, or groups of genes whose products have related functions and which are transcribed as a unit.
- By contrast, eukaryotic genes are transcribed only one at a time but may include long
stretches of DNA called introns which are transcribed but never translated into protein (they are spliced out before translation). Splicing can also occur in prokaryotic genes but is less common than in eukaryotes.
Repetitive DNA in eukaryotic genomes
- High-throughput DNA sequencing reveals huge numbers of repetitive sequences in eukaryotic chromosomes. Many questions are open about the origin, evolutionary mode, and functions that
repetitive sequences might have in the genome. - Some of the satellite DNAs are present in long arrays of similar motifs at a small number of sites, while others, particularly the transposable elements (DNA transposons and retrotransposons), are dispersed over regions of the genome; in both cases, sequence motifs may be located at relatively specific chromosome domains such as centromeres or subtelomeric regions.
- Some repetitive sequences are extremely well conserved between species, while others are among the most variable, defining differences between even closely related species.
There are three main types of DNA sequences:
- Unique or non-repetitive
- Moderately repetitive
- Highly repetitive
Unique or non-repetitive sequences – It is found once or a few times in the genome. Mostly Includes structural genes as well as intergenic areas.
Moderately repetitive sequences– About half the human genome is made up of moderately repeated sequences that are derived from transposable elements— segments of DNA, ranging from a few hundred to several thousand base pairs long.
Highly repetitive sequences– Another 3% or so of the human genome consists of highly repetitive sequences, also referred to as simple-sequence DNA or simple sequence repeats (SSR).
Satellite DNA – are short sequences (about five to a few hundred base pairs in length) that form very large clusters, each containing up to several million base pairs of DNA. The base composition of these DNA segments is sufficiently different from the bulk of the DNA that fragments containing the sequence can be separated into a distinct “satellite” band during density gradient centrifugation.
Minisatellite DNA– sequences range from about 10 to 100 base pairs in length and are found in sizeable clusters containing as many as 3000 repeats.
Microsatellite DNAs – shortest sequences (1 to 9 base pairs long) and are typically present in small clusters of about 10 to 40 base pairs in length, which are scattered quite evenly through the genome.
Interrupted Gene
- Genes are located along the length of the chromosome between the centromere and telomere.
- A hundred to thousand genes might be located on one chromosome. In lower eukaryotic
organisms like yeast lesser number of the short genes, and segments are present with very few introns. But in higher eukaryotic cells like mammalian cells, the number of genes is large with many introns. - The non-gene part of a chromosome includes the telomere, centromere, and characteristic repetitive sequences.
- Approximately 2% of the eukaryotic genome codes for polypeptides (exons), with the remainder as noncoding DNA; noncoding DNA is associated with genes as regulatory sequences or as intervening (intron) sequences, with the remainder as either pseudogenes or repetitive DNA.
Gene family
- The members of a gene family have a common organization A common feature in a set of genes is assumed to identify a property that preceded their separation in evolution.
- All globin genes have a common form of organization with 3 exons and 2 introns, suggesting that they are descended from a single ancestral gene.
- A fascinating case of evolutionary conservation is presented by the α-and β-globins and two other proteins related to them.
- Myoglobin is a monomeric oxygen-binding protein of animals, whose amino acid sequence suggests a common (though ancient) origin with the globin subunits.
- Leghemoglobins are oxygen-binding proteins present in the legume class of plants; like myoglobin, they are monomeric. They too share a common origin with the other heme-binding proteins.
- Together, the globins, myoglobin, and leghemoglobin constitute the globin superfamily, a set of gene families all descended from some (distant) common ancestor.
Download CSIR UNIT 2 Notes FULL PDF Below.
What Cellular Structure Holds the Genetic Information?
Chromosomes – contain the genetic material: DNA, RNA
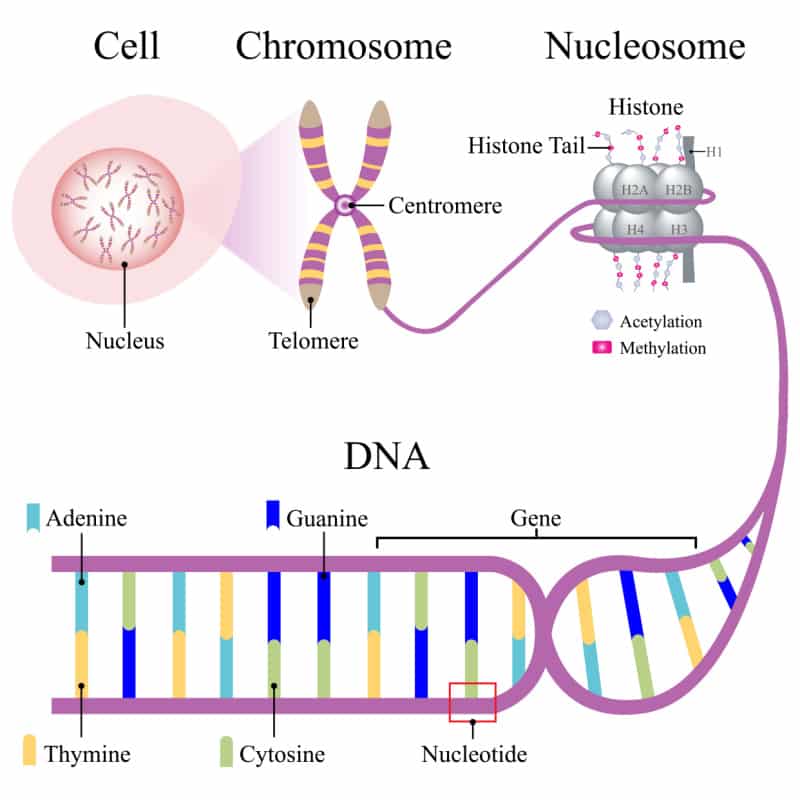
Chromatin – Is the chromosomal material in its decondensed, threadlike state.
Chromosomes
- They are huge: One bp = 600 daltons, an average chromosome is 10^7 bp long = 10^9- 10^10 dalton!
- They contain a huge amount of non-redundant information (it is not just a big repetitive polymer but it has a unique sequence).
- There is only one such molecule in each cell. (unlike any other molecule when lost it cannot be re-synthesized from scratch or imported)
- Philosophically – the cell is there to serve, protect and propagate the chromosomes. Practically – the chromosome must be protected at the ends – telomeres and it must have “something” that will enable it to be moved to daughter cells –
centromeres
Centromere – Download Full Notes Below:
CSIR NET UNIT 1(A) Notes – Structure of Atoms, Molecules & Chemical Bonds – Download FREE PDF



 2026 Notification Released – Check Eligibility, Syllabus & Apply Online")










